В отличие от громоздких облачных сервисов, которые требуют постоянного подключения к интернету и зачастую просят доступ к личным данным, gImageReader работает напрямую на вашем компьютере с Windows. Эта программа создана для тех, кто устал перепечатывать текст с фотографий документов, скриншотов или сканов. По сути, это графическая оболочка для мощного движка распознавания Tesseract OCR, но не пугайтесь технических подробностей — разработчики сделали интерфейс максимально понятным даже для новичка.
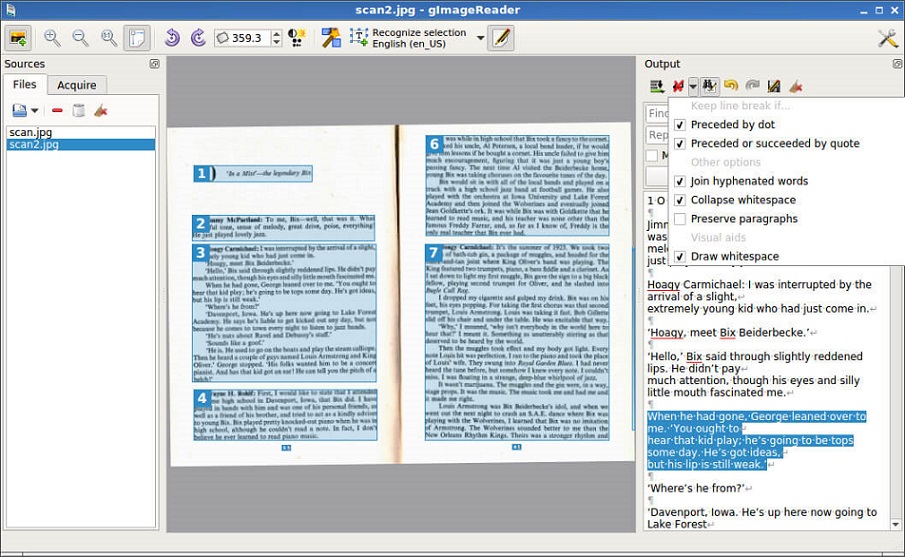
Как это работает на практике? Вы просто перетаскиваете изображение или PDF-файл в главное окно. После этого программа анализирует картинку, выделяет блоки с текстом и предлагает сохранить результат в удобном формате. Лично меня подкупает то, что gImageReader не пытается быть «универсальным комбайном» — она делает ровно одну вещь, но делает её отлично. Нет рекламы, нет навязчивых предложений купить премиум-аккаунт, нет бесконечных регистраций.
Важный момент, о котором часто молчат обзоры: программа прекрасно справляется с многоязычными документами. Если вам нужно распознать текст, где русский перемежается с английским или немецким, gImageReader не сломается. Можно выбрать несколько языков одновременно, и движок сам определит, где какой алфавит. Это реально полезно для работы с технической документацией или научными статьями.
Скачать бесплатно gImageReader 3.4.3 x64
Скачать бесплатно gImageReader 3.4.3 x32
Пароль ко всем архивам: 1progs
Конечно, идеального софта не бывает. Интерфейс выглядит так, будто его делали инженеры, а не дизайнеры — всё строго, серо и функционально. Некоторых это отпугивает, но я считаю, что для инструмента, который запускают пару раз в день, внешний вид не главное. Куда важнее, что gImageReader умеет работать с повернутыми страницами и неплохо восстанавливает размытый текст. С фотографиями, сделанными на телефон в спешке, справляется приемлемо — хотя идеального качества ждать не стоит.
В программе есть встроенная функция редактирования зон распознавания. Вы можете вручную указать, какую область картинки нужно обрабатывать, а какую игнорировать. Это спасает, когда на скане есть пометки от руки, колонтитулы или хаотично расположенные графики. Просто обводите мышкой нужный прямоугольник — и gImageReader фокусируется только на нём.
Разработчики не гонятся за трендами и не пихают нейросети куда попало. Из расширенных возможностей — разве что экспорт в PDF с поиском по тексту. То есть вы сканируете бумажный договор, программа распознаёт его, и на выходе получается полноценный PDF, где работает поиск Ctrl+F. Очень удобно для юристов, бухгалтеров и всех, кто хранит архивы документов.
Системные требования минимальные: gImageReader запустится даже на старом ноутбуке с Windows 7. Установщик весит немного, не тянет за собой «левых» программ и не прописывается в автозагрузку без спроса. Единственное, что стоит учесть — для работы с русским языком нужно при первом запуске скачать языковой пакет через меню программы. Это делается в два клика, но многие пропускают этот шаг и потом пишут гневные отзывы, что «программа не работает».